Database Sharding: Scaling Beyond Single Server Limits
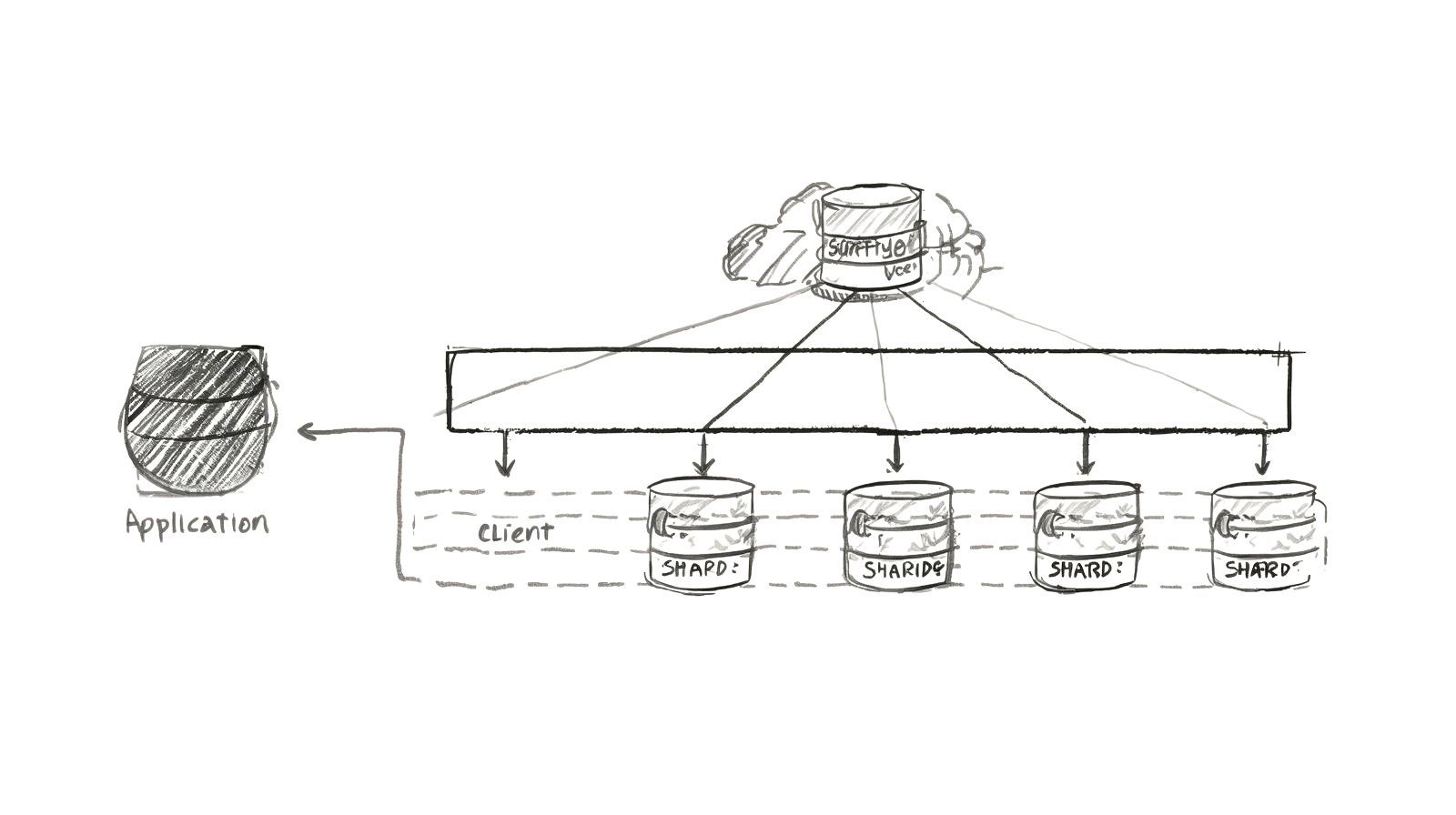
Learn database sharding strategies to scale horizontally. Covers sharding keys, rebalancing, cross-shard queries, and real-world implementation.
This article is also available in Portuguese
What is Database Sharding?
Sharding is horizontal partitioning of data across multiple databases. Instead of one massive database, you split data across multiple smaller databases (shards).
Why Shard?
Single Database Limits:
- Storage capacity (disk space)
- Memory constraints (RAM)
- CPU bottlenecks
- I/O throughput limits
Sharding Benefits:
- Linear scalability (add more servers)
- Better performance (smaller datasets per shard)
- Fault isolation (one shard failure doesn’t kill everything)
- Geographic distribution (data close to users)
Vertical vs Horizontal Partitioning
Vertical Partitioning
Split by features/tables:
Database 1: Users, Auth
Database 2: Orders, Payments
Database 3: Products, Inventory
Horizontal Partitioning (Sharding)
Split same table across multiple databases:
Users Table:
Shard 1: Users 1-1,000,000
Shard 2: Users 1,000,001-2,000,000
Shard 3: Users 2,000,001-3,000,000
Sharding Strategies
1. Range-Based Sharding
Partition data by value ranges.
fun getShardForUser(userId: Long): String = when {
userId <= 1_000_000 -> "shard-1"
userId <= 2_000_000 -> "shard-2"
userId <= 3_000_000 -> "shard-3"
else -> "shard-4"
}
Pros:
- Simple to implement
- Easy to add new ranges
- Range queries are efficient
Cons:
- Uneven distribution (hotspots)
- Rebalancing is complex
Best for: Time-series data (shard by date)
// Shard logs by month
fun getLogShard(timestamp: Long): String {
val instant = Instant.ofEpochMilli(timestamp)
val month = instant.atZone(ZoneId.systemDefault()).monthValue
return "logs-2026-${month.toString().padStart(2, '0')}"
}
2. Hash-Based Sharding
Use hash function to determine shard.
fun getShardForUser(userId: Long): String {
val hash = hashFunction(userId)
val shardCount = 4
val shardIndex = hash % shardCount
return "shard-$shardIndex"
}
fun hashFunction(key: Any): Int {
val str = key.toString()
var hash = 0
str.forEach { char ->
hash = ((hash shl 5) - hash) + char.code
hash = hash and hash // Convert to 32-bit integer
}
return kotlin.math.abs(hash)
}
Pros:
- Even distribution
- No hotspots
Cons:
- Range queries are impossible
- Resharding requires moving all data
Best for: Evenly distributed access patterns
3. Consistent Hashing
Minimizes data movement when adding/removing shards.
class ConsistentHash(
shards: List<String>,
private val virtualNodes: Int = 150
) {
private val ring = mutableMapOf<Int, String>()
private val shards = shards.toMutableList()
private var sortedKeys: List<Int>
init {
// Create virtual nodes for each shard
shards.forEach { shard ->
repeat(virtualNodes) { i ->
val virtualKey = "$shard-$i"
val hash = hash(virtualKey)
ring[hash] = shard
}
}
// Sort ring by hash value
sortedKeys = ring.keys.sorted()
}
fun getShard(key: String): String? {
if (sortedKeys.isEmpty()) return null
val hash = hash(key)
// Find first node >= hash
sortedKeys.forEach { nodeHash ->
if (nodeHash >= hash) {
return ring[nodeHash]
}
}
// Wrap around to first node
return ring[sortedKeys.first()]
}
private fun hash(key: String): Int {
var hash = 0
key.forEach { char ->
hash = ((hash shl 5) - hash) + char.code
hash = hash and hash
}
return kotlin.math.abs(hash)
}
fun addShard(shard: String) {
shards.add(shard)
repeat(virtualNodes) { i ->
val virtualKey = "$shard-$i"
val hash = hash(virtualKey)
ring[hash] = shard
}
sortedKeys = ring.keys.sorted()
}
}
// Usage
val sharding = ConsistentHash(listOf("shard-1", "shard-2", "shard-3"))
val shard = sharding.getShard("user-12345")
println(shard) // shard-2
Pros:
- Minimal data movement on resharding
- Even distribution
Cons:
- More complex to implement
Best for: Dynamic sharding environments
4. Geographic Sharding
Shard by user location.
fun getShardForUser(userId: Long): String {
val user = getUserLocation(userId)
return when (user.country) {
"US" -> "us-shard"
"UK" -> "eu-shard"
"JP" -> "asia-shard"
else -> "default-shard"
}
}
Best for:
- Reducing latency
- Data sovereignty compliance (GDPR)
- Multi-region applications
5. Directory-Based Sharding
Maintain a lookup table for shard locations.
// Shard directory (typically in Redis or database)
val shardDirectory = mapOf(
"user-1" to "shard-1",
"user-2" to "shard-1",
"user-3" to "shard-2",
"user-4" to "shard-3",
// ... millions of entries
)
fun getShardForUser(userId: Long): String? {
return shardDirectory["user-$userId"]
}
Pros:
- Flexible assignment
- Easy to rebalance specific keys
Cons:
- Directory becomes a bottleneck
- Directory must be highly available
Solution: Cache directory in application memory, use Redis for persistence.
Choosing a Shard Key
The shard key determines data distribution. Choose wisely!
Good Shard Key Characteristics
- High Cardinality: Many unique values
- Even Distribution: No hotspots
- Immutable: Doesn’t change over time
- Query-Aligned: Supports common queries
Examples
// ✅ Good shard keys
userId // High cardinality, immutable
email // Unique, immutable
orderId // High cardinality
// ❌ Bad shard keys
country // Low cardinality (hotspots)
status // Low cardinality
createdDate // Changes over time (time-based hotspot)
Multi-Column Shard Keys
Combine multiple fields for better distribution:
// Shard by (tenant_id, user_id)
fun getShard(tenantId: String, userId: Long): Int {
val key = "$tenantId-$userId"
return hashFunction(key) % shardCount
}
Handling Cross-Shard Operations
The biggest challenge with sharding!
1. Cross-Shard Queries
// Query all shards and merge results
suspend fun searchUsers(searchQuery: String): List<User> {
val shards = listOf("shard-1", "shard-2", "shard-3")
val results = coroutineScope {
shards.map { shard ->
async {
queryDatabase(shard, "SELECT * FROM users WHERE name LIKE ?", searchQuery)
}
}.awaitAll()
}
// Merge and sort results
return results
.flatten()
.sortedBy { it.createdAt }
.take(100) // Limit
}
Performance tip: Parallel queries reduce latency.
2. Cross-Shard Joins
Avoid if possible! If you must:
// Application-level join
suspend fun getUsersWithOrders(): List<UserWithOrders> {
// Get users from user shard
val users = queryUserShard("SELECT * FROM users")
// Get orders for each user
val userIds = users.map { it.id }
val orders = coroutineScope {
userIds.map { id ->
async {
queryOrderShard(id, "SELECT * FROM orders WHERE user_id = ?")
}
}.awaitAll()
}
// Join in application
return users.mapIndexed { index, user ->
UserWithOrders(
user = user,
orders = orders[index]
)
}
}
data class UserWithOrders(
val user: User,
val orders: List<Order>
)
Better solution: Denormalize data to avoid joins.
3. Cross-Shard Transactions
Challenge: ACID transactions across shards are very hard.
Solutions:
Two-Phase Commit (2PC):
async function transferMoney(fromUserId, toUserId, amount) {
const fromShard = getShardForUser(fromUserId);
const toShard = getShardForUser(toUserId);
// Phase 1: Prepare
const tx1 = await fromShard.begin();
const tx2 = await toShard.begin();
try {
await tx1.execute('UPDATE accounts SET balance = balance - ? WHERE user_id = ?', [amount, fromUserId]);
await tx2.execute('UPDATE accounts SET balance = balance + ? WHERE user_id = ?', [amount, toUserId]);
// Phase 2: Commit
await tx1.commit();
await tx2.commit();
} catch (error) {
// Rollback both
await tx1.rollback();
await tx2.rollback();
throw error;
}
}
Saga Pattern (Better for microservices):
async function transferMoney(fromUserId, toUserId, amount) {
const transferId = generateId();
try {
// Step 1: Debit from account
await debitAccount(fromUserId, amount, transferId);
// Step 2: Credit to account
await creditAccount(toUserId, amount, transferId);
} catch (error) {
// Compensating transaction
await refundAccount(fromUserId, amount, transferId);
throw error;
}
}
Rebalancing Shards
When adding new shards, you need to move data.
Planned Rebalancing
async function rebalanceShard(oldShard, newShard, keyRange) {
// 1. Start dual writes (write to both shards)
enableDualWrites(oldShard, newShard, keyRange);
// 2. Copy existing data
const data = await oldShard.query('SELECT * FROM users WHERE id BETWEEN ? AND ?', keyRange);
await newShard.bulkInsert('users', data);
// 3. Verify data integrity
const verified = await verifyData(oldShard, newShard, keyRange);
if (!verified) throw new Error('Data verification failed');
// 4. Switch reads to new shard
updateShardMapping(keyRange, newShard);
// 5. Stop dual writes, delete from old shard
disableDualWrites(oldShard, keyRange);
await oldShard.delete('DELETE FROM users WHERE id BETWEEN ? AND ?', keyRange);
}
Monitoring Sharded Databases
Essential metrics:
// Per-shard metrics
{
shard: 'shard-1',
metrics: {
storage_used: '450GB',
query_latency_p95: '45ms',
queries_per_second: 5000,
connection_pool: { active: 80, idle: 20 },
hottest_keys: ['user-12345', 'user-67890']
}
}
Watch for:
- Hotspots (one shard much busier)
- Storage imbalance
- Slow queries
- Connection pool saturation
Real-World Example: Instagram
Instagram shards by user ID:
- User joins → assigned to least-loaded shard
- All user data (posts, follows) goes to same shard
- Shard lookup cached in Redis
- Cross-shard queries use fan-out approach
Best Practices
- Start with vertical partitioning before sharding
- Choose shard key carefully - hard to change later
- Avoid cross-shard operations when possible
- Denormalize data to keep related data together
- Monitor shard balance proactively
- Plan for rebalancing from day one
- Use consistent hashing for dynamic environments
- Cache shard mappings in application
- Implement circuit breakers for shard failures
- Test failover scenarios regularly
When NOT to Shard
- You have < 1TB of data
- Single server handles your load
- You can scale vertically (bigger server)
- Your team lacks distributed systems expertise
Remember: Sharding adds significant complexity. Exhaust all other options first!
Conclusion
Sharding is a powerful technique for scaling databases beyond single-server limits. Key takeaways:
- Choose the right sharding strategy for your use case
- Select a good shard key (high cardinality, immutable)
- Minimize cross-shard operations
- Plan for rebalancing
- Monitor shard health continuously
Sharding is the last resort, not the first choice. But when you need it, implementing it correctly makes all the difference.
Happy sharding! 🔪