Sharding de Banco de Dados: Escalando Além dos Limites de um Servidor
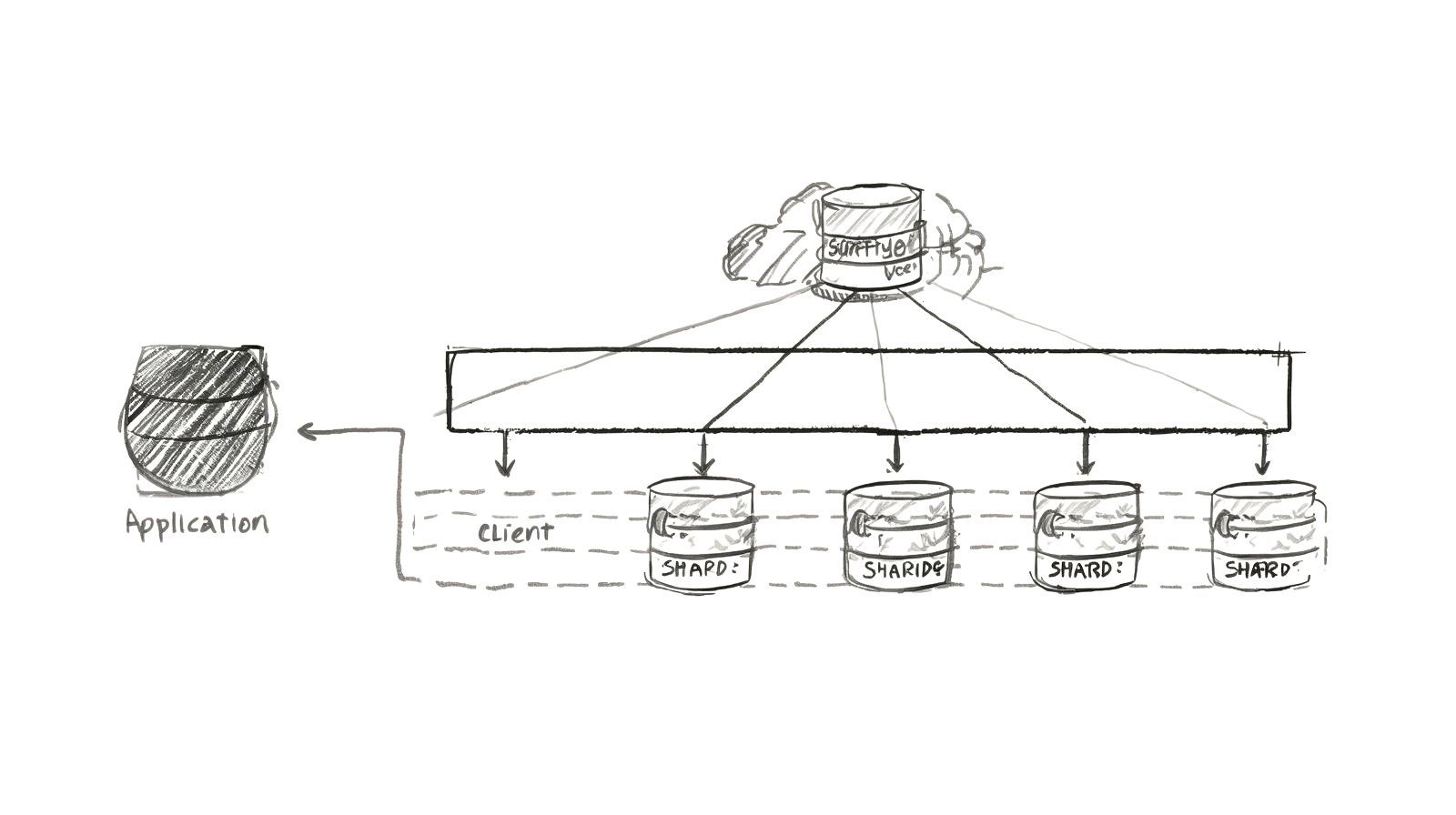
Aprenda estratégias de sharding de banco de dados para escalar horizontalmente. Cobre chaves de sharding, rebalanceamento, queries cross-shard e implementação real.
Este artigo também está disponível em inglês
O Que é Sharding de Banco de Dados?
Sharding é o particionamento horizontal de dados através de múltiplos bancos de dados. Ao invés de um banco de dados massivo, você divide os dados através de vários bancos menores (shards).
Por Que Fazer Sharding?
Limites de Banco Único:
- Capacidade de armazenamento (espaço em disco)
- Restrições de memória (RAM)
- Gargalos de CPU
- Limites de throughput I/O
Benefícios do Sharding:
- Escalabilidade linear (adicione mais servidores)
- Melhor performance (conjuntos de dados menores por shard)
- Isolamento de falhas (uma falha de shard não derruba tudo)
- Distribuição geográfica (dados próximos aos usuários)
Particionamento Vertical vs Horizontal
Particionamento Vertical
Dividir por features/tabelas:
Banco 1: Usuários, Auth
Banco 2: Pedidos, Pagamentos
Banco 3: Produtos, Inventário
Particionamento Horizontal (Sharding)
Dividir mesma tabela através de múltiplos bancos:
Tabela Users:
Shard 1: Usuários 1-1.000.000
Shard 2: Usuários 1.000.001-2.000.000
Shard 3: Usuários 2.000.001-3.000.000
Estratégias de Sharding
1. Sharding Baseado em Range
Particionar dados por ranges de valores.
fun getShardForUser(userId: Long): String = when {
userId <= 1_000_000 -> "shard-1"
userId <= 2_000_000 -> "shard-2"
userId <= 3_000_000 -> "shard-3"
else -> "shard-4"
}
Prós:
- Simples de implementar
- Fácil adicionar novos ranges
- Queries de range são eficientes
Contras:
- Distribuição desigual (hotspots)
- Rebalanceamento é complexo
Melhor para: Dados de séries temporais (shard por data)
// Shard logs por mês
fun getLogShard(timestamp: Long): String {
val instant = Instant.ofEpochMilli(timestamp)
val month = instant.atZone(ZoneId.systemDefault()).monthValue
return "logs-2026-${month.toString().padStart(2, '0')}"
}
2. Sharding Baseado em Hash
Usar função hash para determinar shard.
fun getShardForUser(userId: Long): String {
val hash = hashFunction(userId)
val shardCount = 4
val shardIndex = hash % shardCount
return "shard-$shardIndex"
}
fun hashFunction(key: Any): Int {
val str = key.toString()
var hash = 0
str.forEach { char ->
hash = ((hash shl 5) - hash) + char.code
hash = hash and hash // Converter para inteiro 32-bit
}
return kotlin.math.abs(hash)
}
Prós:
- Distribuição uniforme
- Sem hotspots
Contras:
- Queries de range são impossíveis
- Resharding requer mover todos os dados
Melhor para: Padrões de acesso uniformemente distribuídos
3. Consistent Hashing
Minimiza movimentação de dados ao adicionar/remover shards.
class ConsistentHash(
shards: List<String>,
private val virtualNodes: Int = 150
) {
private val ring = mutableMapOf<Int, String>()
private val shards = shards.toMutableList()
private var sortedKeys: List<Int>
init {
// Criar nós virtuais para cada shard
shards.forEach { shard ->
repeat(virtualNodes) { i ->
val virtualKey = "$shard-$i"
val hash = hash(virtualKey)
ring[hash] = shard
}
}
// Ordenar ring por valor hash
sortedKeys = ring.keys.sorted()
}
fun getShard(key: String): String? {
if (sortedKeys.isEmpty()) return null
val hash = hash(key)
// Encontrar primeiro nó >= hash
sortedKeys.forEach { nodeHash ->
if (nodeHash >= hash) {
return ring[nodeHash]
}
}
// Voltar ao primeiro nó
return ring[sortedKeys.first()]
}
private fun hash(key: String): Int {
var hash = 0
key.forEach { char ->
hash = ((hash shl 5) - hash) + char.code
hash = hash and hash
}
return kotlin.math.abs(hash)
}
fun addShard(shard: String) {
shards.add(shard)
repeat(virtualNodes) { i ->
val virtualKey = "$shard-$i"
val hash = hash(virtualKey)
ring[hash] = shard
}
sortedKeys = ring.keys.sorted()
}
}
// Uso
val sharding = ConsistentHash(listOf("shard-1", "shard-2", "shard-3"))
val shard = sharding.getShard("user-12345")
println(shard) // shard-2
Prós:
- Mínima movimentação de dados no resharding
- Distribuição uniforme
Contras:
- Mais complexo de implementar
Melhor para: Ambientes dinâmicos de sharding
4. Sharding Geográfico
Shard por localização do usuário.
fun getShardForUser(userId: Long): String {
val user = getUserLocation(userId)
return when (user.country) {
"BR" -> "br-shard"
"US" -> "us-shard"
"UK" -> "eu-shard"
else -> "default-shard"
}
}
Melhor para:
- Reduzir latência
- Conformidade com soberania de dados (LGPD/GDPR)
- Aplicações multi-região
5. Sharding Baseado em Diretório
Manter tabela de lookup para localizações de shard.
// Diretório de shards (normalmente em Redis ou banco)
val shardDirectory = mapOf(
"user-1" to "shard-1",
"user-2" to "shard-1",
"user-3" to "shard-2",
"user-4" to "shard-3",
// ... milhões de entradas
)
fun getShardForUser(userId: Long): String? {
return shardDirectory["user-$userId"]
}
Prós:
- Atribuição flexível
- Fácil rebalancear chaves específicas
Contras:
- Diretório se torna gargalo
- Diretório deve ser altamente disponível
Solução: Cachear diretório na memória da aplicação, usar Redis para persistência.
Escolhendo uma Chave de Shard
A chave de shard determina distribuição de dados. Escolha sabiamente!
Boas Características de Chave de Shard
- Alta Cardinalidade: Muitos valores únicos
- Distribuição Uniforme: Sem hotspots
- Imutável: Não muda com o tempo
- Alinhada com Queries: Suporta queries comuns
Exemplos
// ✅ Boas chaves de shard
userId // Alta cardinalidade, imutável
email // Único, imutável
orderId // Alta cardinalidade
// ❌ Más chaves de shard
country // Baixa cardinalidade (hotspots)
status // Baixa cardinalidade
createdDate // Muda com tempo (hotspot temporal)
Chaves de Shard Multi-Coluna
Combinar múltiplos campos para melhor distribuição:
// Shard por (tenant_id, user_id)
fun getShard(tenantId: String, userId: Long): Int {
val key = "$tenantId-$userId"
return hashFunction(key) % shardCount
}
Lidando com Operações Cross-Shard
O maior desafio com sharding!
1. Queries Cross-Shard
// Query todos os shards e mesclar resultados
suspend fun searchUsers(searchQuery: String): List<User> {
val shards = listOf("shard-1", "shard-2", "shard-3")
val results = coroutineScope {
shards.map { shard ->
async {
queryDatabase(shard, "SELECT * FROM users WHERE name LIKE ?", searchQuery)
}
}.awaitAll()
}
// Mesclar e ordenar resultados
return results
.flatten()
.sortedBy { it.createdAt }
.take(100) // Limitar
}
Dica de performance: Queries paralelas reduzem latência.
2. Joins Cross-Shard
Evite se possível! Se necessário:
// Join em nível de aplicação
suspend fun getUsersWithOrders(): List<UserWithOrders> {
// Buscar usuários do shard de usuários
val users = queryUserShard("SELECT * FROM users")
// Buscar pedidos para cada usuário
val userIds = users.map { it.id }
val orders = coroutineScope {
userIds.map { id ->
async {
queryOrderShard(id, "SELECT * FROM orders WHERE user_id = ?")
}
}.awaitAll()
}
// Join na aplicação
return users.mapIndexed { index, user ->
UserWithOrders(
user = user,
orders = orders[index]
)
}
}
data class UserWithOrders(
val user: User,
val orders: List<Order>
)
Melhor solução: Desnormalizar dados para evitar joins.
3. Transações Cross-Shard
Desafio: Transações ACID entre shards são muito difíceis.
Soluções:
Two-Phase Commit (2PC):
async function transferMoney(fromUserId, toUserId, amount) {
const fromShard = getShardForUser(fromUserId);
const toShard = getShardForUser(toUserId);
// Fase 1: Preparar
const tx1 = await fromShard.begin();
const tx2 = await toShard.begin();
try {
await tx1.execute('UPDATE accounts SET balance = balance - ? WHERE user_id = ?', [amount, fromUserId]);
await tx2.execute('UPDATE accounts SET balance = balance + ? WHERE user_id = ?', [amount, toUserId]);
// Fase 2: Commit
await tx1.commit();
await tx2.commit();
} catch (error) {
// Rollback ambos
await tx1.rollback();
await tx2.rollback();
throw error;
}
}
Padrão Saga (Melhor para microserviços):
async function transferMoney(fromUserId, toUserId, amount) {
const transferId = generateId();
try {
// Passo 1: Débito da conta
await debitAccount(fromUserId, amount, transferId);
// Passo 2: Crédito na conta
await creditAccount(toUserId, amount, transferId);
} catch (error) {
// Transação compensatória
await refundAccount(fromUserId, amount, transferId);
throw error;
}
}
Monitorando Bancos Sharded
Métricas essenciais:
// Métricas por shard
{
shard: 'shard-1',
metrics: {
storage_used: '450GB',
query_latency_p95: '45ms',
queries_per_second: 5000,
connection_pool: { active: 80, idle: 20 },
hottest_keys: ['user-12345', 'user-67890']
}
}
Fique atento a:
- Hotspots (um shard muito mais ocupado)
- Desbalanceamento de armazenamento
- Queries lentas
- Saturação de connection pool
Boas Práticas
- Comece com particionamento vertical antes de sharding
- Escolha chave de shard cuidadosamente - difícil mudar depois
- Evite operações cross-shard quando possível
- Desnormalize dados para manter dados relacionados juntos
- Monitore balanceamento de shards proativamente
- Planeje rebalanceamento desde o dia um
- Use consistent hashing para ambientes dinâmicos
- Cacheie mapeamentos de shard na aplicação
- Implemente circuit breakers para falhas de shard
- Teste cenários de failover regularmente
Quando NÃO Fazer Sharding
- Você tem < 1TB de dados
- Servidor único lida com sua carga
- Você pode escalar verticalmente (servidor maior)
- Sua equipe não tem expertise em sistemas distribuídos
Lembre-se: Sharding adiciona complexidade significativa. Esgote todas as outras opções primeiro!
Conclusão
Sharding é uma técnica poderosa para escalar bancos além dos limites de servidor único. Principais lições:
- Escolha a estratégia de sharding certa para seu caso de uso
- Selecione uma boa chave de shard (alta cardinalidade, imutável)
- Minimize operações cross-shard
- Planeje rebalanceamento
- Monitore saúde dos shards continuamente
Sharding é o último recurso, não a primeira escolha. Mas quando você precisa, implementar corretamente faz toda a diferença.
Feliz sharding! 🔪